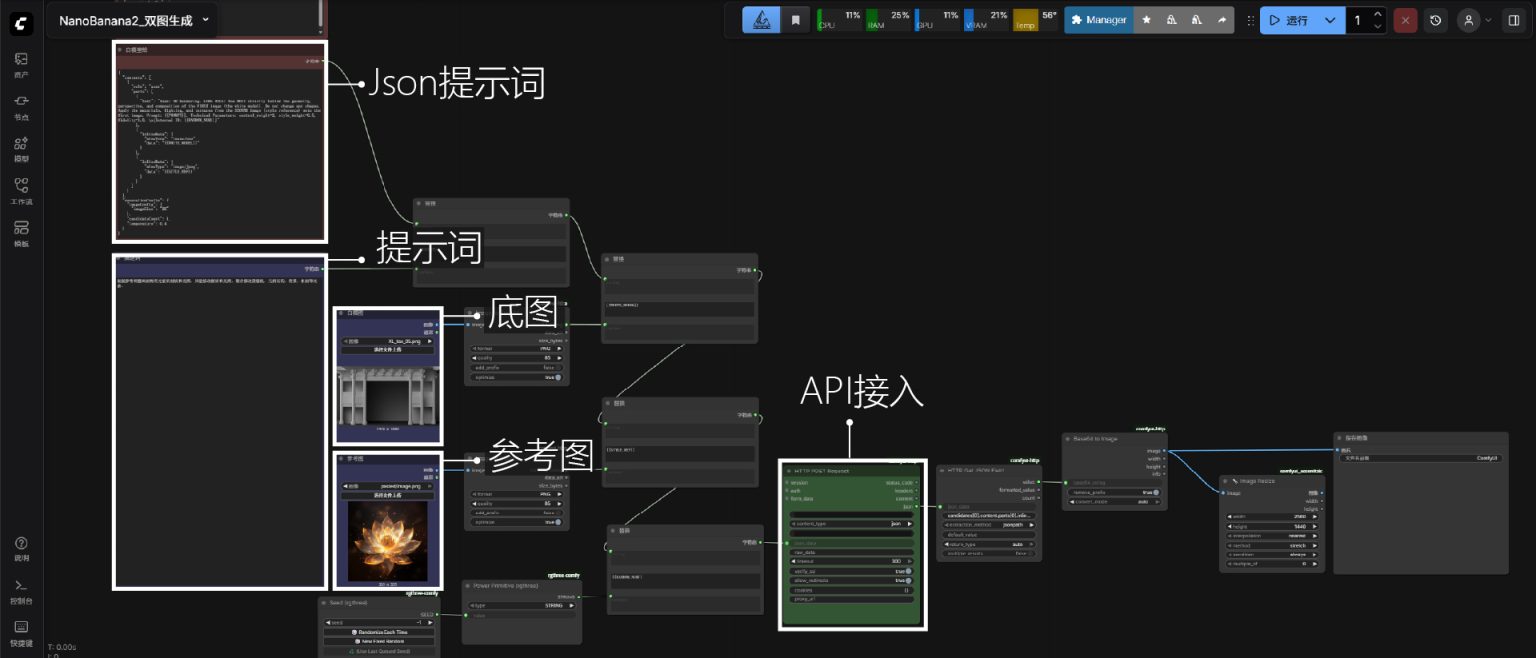
{ “contents”: [ { “role”: “user”, “parts”: [ { “text”: “Task: 3D Rendering. CORE RULE: You MUST strictly follow the geometry, perspective, and composition of the FIRST image (the white model). Do not change any shapes. Apply the materials, lighting, and textures from the SECOND image (style reference) onto the first image. Prompt: {{PROMPT}}. Technical Parameters: control_weight=2, style_weight=0.5, fidelity=1.0. \n[Internal ID: {{RANDOM_NUM}}]” }, { “inlineData”: { “mimeType”: “image/png”, “data”: “{{WHITE_MODEL}}” } }, { “inlineData”: { “mimeType”: “image/jpeg”, “data”: “{{STYLE_REF}}” } } ] } ], “generationConfig”: { “imageConfig”: { “imageSize”: “2K” }, “candidateCount”: 1, “temperature”: 0.4 } }